
Проверка проходит в фоновом режиме, страничка зависает на время выполнения скрипта. Не закрывайте и не обновляйте страничку, результаты загрузятся, как пройдет проверка. Чем больше ссылок, тем больше ожидание. Примерно 1 ссылку главной страницы проверяет примерно 10-20 секунд, внутреннюю около 30-60 секунд (зависит также от сервера, на котором расположен сайт), 3 ссылки около 2-3 минуты. На главную страницу требуется меньше времени, чем на внутреннюю (для них больше проверок)
Конечно, часть дублей можно увидеть в Яндекс Вебмастере или Google Search Console, но как показывает практика, там зачастую не показывает и половины дубликатов страниц на сайте в поиске и вне индекса, которые мешают SEO продвижению сайта. Большое количество дублей можно узнать через какую-нибудь SEO программу, по типу Screaming Frog. Но проблема в том, что данные парсеры показывают лишь только те дубли, на которые есть ссылки с сайта. Т.е. в основном это полные дубли контента или частичные дубли в виде страниц пагинации (но с одинаковыми мета-тегами), на которые ссылается сайт. Потенциальные же дубли они не проверяют. В итоге не работая с потенциальной проблемой, придется постоянно исправлять постфактум проблемы с дублированием страниц.
Большое же количество дублей могут просто «потопить» сайт, возникновение дублирующих страниц мешают нормальной индексации и сразу отображаются на позициях сайта в поисковой выдаче.
Как трактовать результаты проверки?
Проверка дублей страниц для главной страницы
После получения результатов, вы видите подобную таблицу. В данном случае для примера приведу результаты для главной страницы
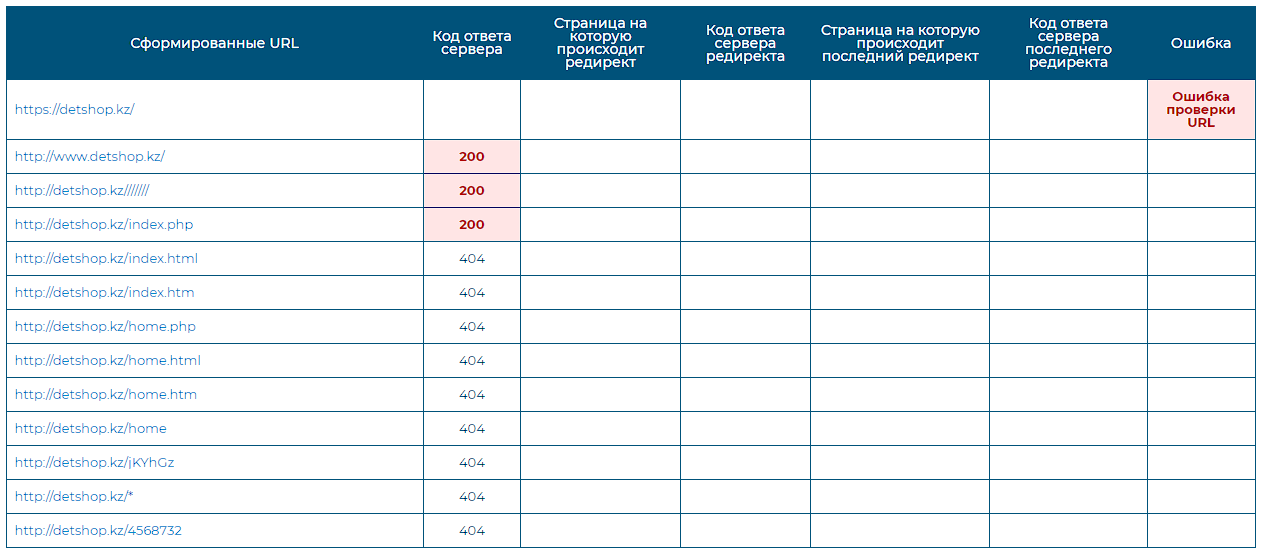
На скриншоте выше можно наблюдать такие дубли, где у нас проблема с HTTPS протоколом, страница, которая не открывается, выдает ошибку сертификата SSL, поэтому возникла «Ошибка проверки URL».
Далее мы видим ошибки и наличие дублей, которые нужно исправить:
- Не выбрано зеркало, с WWW или без WWW, соответственно не настроен редирект. Страница доступна по обоим адресам
- Нет редиректа при добавлении множественных слешей.
- Также страница открывается с добавлением /index.php, что является также дублем проверяемой страницы.
Остальные проверки страничка прошла. Соответственно в данной ситуации должен быть добавлен SSL сертификат, надо настроить редиректы с HTTP на HTTPS протокол, редирект с множественных слешей, а также редирект с index.php.
Поиск дублей для внутренней страницы
Теперь проверим отдельную страницу, внутреннюю страницу сайта, в данном случае интернет-магазина, чтобы найти дубли
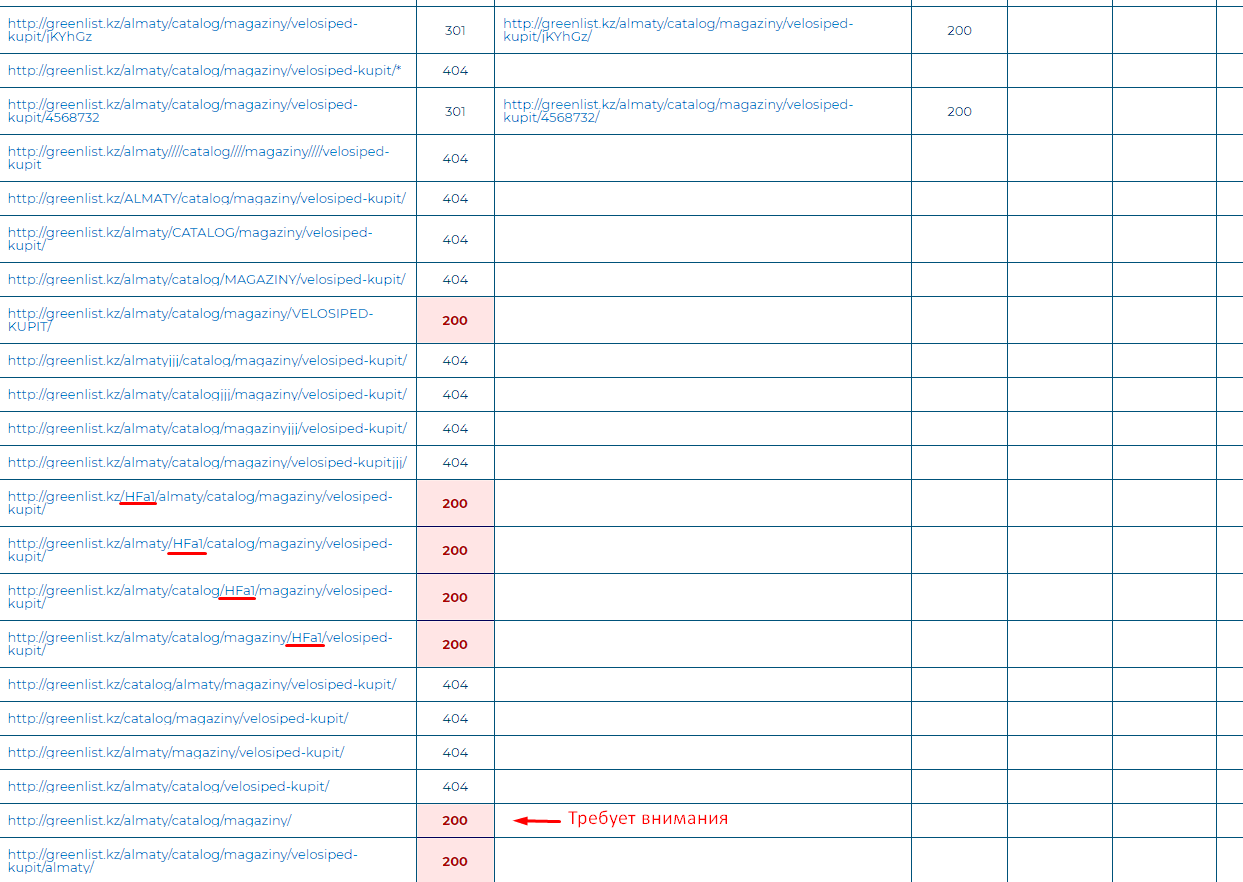
Какие тут можно заметить проблемные места:
- Страница доступная, как с ПРОПИСНЫМИ буквами в URL-адресе, так и со строчными. Это разные страницы для поисковых систем, а посему такие страницы являются дублями.
- Далее идет ряд проверок, в которых добавляется символы /HFa1/, при которых по идеи должна отдаваться 404 ответ сервера (страница не найдена), но отдается 200 код ответа сервера, сервер отдает страничку несмотря на посторонние символы в URL-адресе. Еще может возникнуть куча дублей при такой настройке сервера.
- Предпоследний пункт, в котором убирается последняя часть урла между слешами не всегда показывает на проблему, и что там дубли. Но такая проверка необходима, т.к. не везде соблюдается иерархическая структура URL-адреса и при убирании последней части слеша, возможно выявить проблемы. Здесь надо всегда смотреть вручную, открывать URL и смотреть что открылось, допустимо ли это или нет.
- В последней проверке, меняется порядком часть URL’a, где http://greenlist.kz/almaty/catalog/magaziny/velosiped-kupit/ дублируется в конце URL-адреса и страница всё равно отдает 200 код, хотя должна 404 в данном случае.
Здесь решением проблемы будет настройка редиректа с ПРОПИСНЫХ на строчные буквы, а также настройка сервера (скорее всего, через программиста/разработчиков сайта), чтобы проверялся URL и при наличии ненужных символов отдавался соответствующий 404 ответ сервера.
Можно ли самому исправить дубли сайта?
Да, для этого на сайте есть раздел с редиректами, о которых я расскажу чуть ниже. Собственно, ниже будет таблица, как проходит проверка и как это можно исправить.
| Проверяемый URL-адрес | Описание проверки | Как исправить |
| http://site.com/catalog/noutbuki/c207 | Проверяем HTTP протокол (если подается URL с HTTP протоколом для проверки, проверяем соответственно HTTPS протокол) | Делаем редирект с HTTP на HTTPS |
| https://www.site.com/catalog/noutbuki/c207 | Подставляем WWW к домену (если подали URL уже сразу с WWW, то проверяем без WWW) | Редирект с WWW на без WWW Редирект с без WWW на WWW |
| https://site.com/catalog/noutbuki/c207/////// | Добавляем множественные слеши в конец урла | Редирект для борьбы со множественными слешами |
| https://site.com/catalog/noutbuki/c207/ | Добавляем в конец слеш (если в конце уже есть слеш, то проверяем без слеша) | Добавляем и или убираем в конце URL-адреса слеш |
| https://site.com/catalog/noutbuki/c207/index.php | Добавляем в конец урла /index.php | Убираем index.php с помощью редиректа |
| https://site.com/catalog/noutbuki/c207/home.php | Добавляем в конец урла /home.php | Делаем по аналогии с index.php, только вместо index пишем home |
| https://site.com/catalog/noutbuki/c207/index.html | Добавляем в конец урла /index.html | См. выше про index.php |
| https://site.com/catalog/noutbuki/c207/home.html | Добавляем в конец урла /home.html | См. выше про index.php |
| https://site.com/catalog/noutbuki/c207/index.htm | Добавляем в конец урла /index.htm | См. выше про index.php |
| https://site.com/catalog/noutbuki/c207/home.htm | Добавляем в конец урла /home.htm | См. выше про index.php |
| https://site.com/catalog/noutbuki/c207/home | Добавляем в конец урла /index.php | См. выше про index.php |
| https://site.com/catalog/noutbuki/c207/jKYhGz | Добавляем в конец урла /jKYhGz проверяем на предмет доступности страницы по несуществующему адресу. Если открывает страничку и отдает 200 ответ сервера, то плохая проверка урлов при маршрутизации вашего движка. | Тут редиректами не решить вопрос, если не костылить. Желательно обратиться к программистам, чтобы сделали проверку URL-адресов, дабы не открывались несуществующие URL’ы. |
| https://site.com/catalog/noutbuki/c207/* | Добавляем в конец урла звездочку * | Убираем звездочку из URL |
| https://site.com/catalog/noutbuki/c207/4568732 | Добавляем в конец урла /4568732. Это аналогично предыдущей проверке, но с цифрами. Некоторые CMS считают цифры за ID записи*товара, поэтому вполне могут открыть страничку с 200 кодом | Тут также, если сервер отдает 200 код, то пишем программисту, чтобы настроил проверку URL’ов, чтобы не открывались несуществующие адреса. |
| https://site.com/catalog///////noutbuki///////c207 | Добавляем множественные слеши во внутрь урла возле каждого слеша после домена | Редирект для борьбы со множественными слешами |
| https://site.com/CATALOG/noutbuki/c207 | Делаем первую секцию урла после домена между слешами ПРОПИСНЫМИ буквами | Настраиваем редирект с ПРОПИСНЫХ букв на строчные |
| https://site.com/catalog/NOUTBUKI/c207 | Делаем вторую часть урла после домена между слешами ПРОПИСНЫМИ буквами | Аналогично варианту выше |
| https://site.com/catalog/noutbuki/C207 | Делаем третью часть урла после домена между слешами ПРОПИСНЫМИ буквами (если будет длинный урл, то проверяем каждую секцию между слешами, т.е. 4, 5, 6, сколько будет) | См. выше |
| https://site.com/catalogjjj/noutbuki/c207 | Добавляем в первой части между слешами после домена jjj. Проверяем на несуществующие урлы. | Все так же, решаем через программиста с запросом на проверку URL’ов. |
| https://site.com/catalog/noutbukijjj/c207 | Добавляем во второй части между слешами jjj | См. выше |
| https://site.com/catalog/noutbuki/c207jjj | Добавляем в третьей части между слешами jjj (если будет длинный урл, то проверяем каждую секцию между слешами, т.е. 4, 5, 6, сколько будет) | См. выше |
| https://site.com/HFa1/catalog/noutbuki/c207 | Вставляем секцию /HFa1/ сразу после домена. Проверка также на несуществующие страницы, но на символы между секциями | И здесь также аналогично идем к разработчику, чтобы настроил проверку на несуществующие URL’ы. |
| https://site.com/catalog/HFa1/noutbuki/c207 | Вставляем секцию /HFa1/ после первой секции слешей | См. выше |
| https://site.com/catalog/noutbuki/HFa1/c207 | Вставляем секцию /HFa1/ после второй секции слешей | См. выше |
| https://site.com/noutbuki/catalog/c207 | Меняем местами первую и вторую секцию между слешами. Казалось бы мы создаем несуществующий URL такой манипуляцией, но нет, иногда страницы открываются. | И здесь тоже понадобится программист. |
| https://site.com/noutbuki/c207 | Убираем первую секцию между слешами сразу после домена | См. выше |
| https://site.com/catalog/c207 | Убираем вторую секцию между слешами | См. выше |
| https://site.com/c207 | Убираем 2 и 3 секцию между слешами (если будет длинный урл, то проверяем каждую секцию между слешами, т.е. 4, 5, 6, сколько будет) | Здесь наличие 200 ответа не всегда говорит о том, что это дубль или ошибка. Структура адресов у всех сайтов разная, поэтому в каких-то случаях это поможет выявить ошибку. А в каких-то случаях, где структура URL’ов иерархическая, то скорее всего ошибкой не будет. И просто откроется родительская категория/раздел. |
| https://site.com/catalog/noutbuki/c207/catalog/ | Дублируем секцию сразу после домена в конец урла | Ну, и под конец, здесь также надо составлять ТЗ разработчикам на исправление несуществующих URL’ов. |